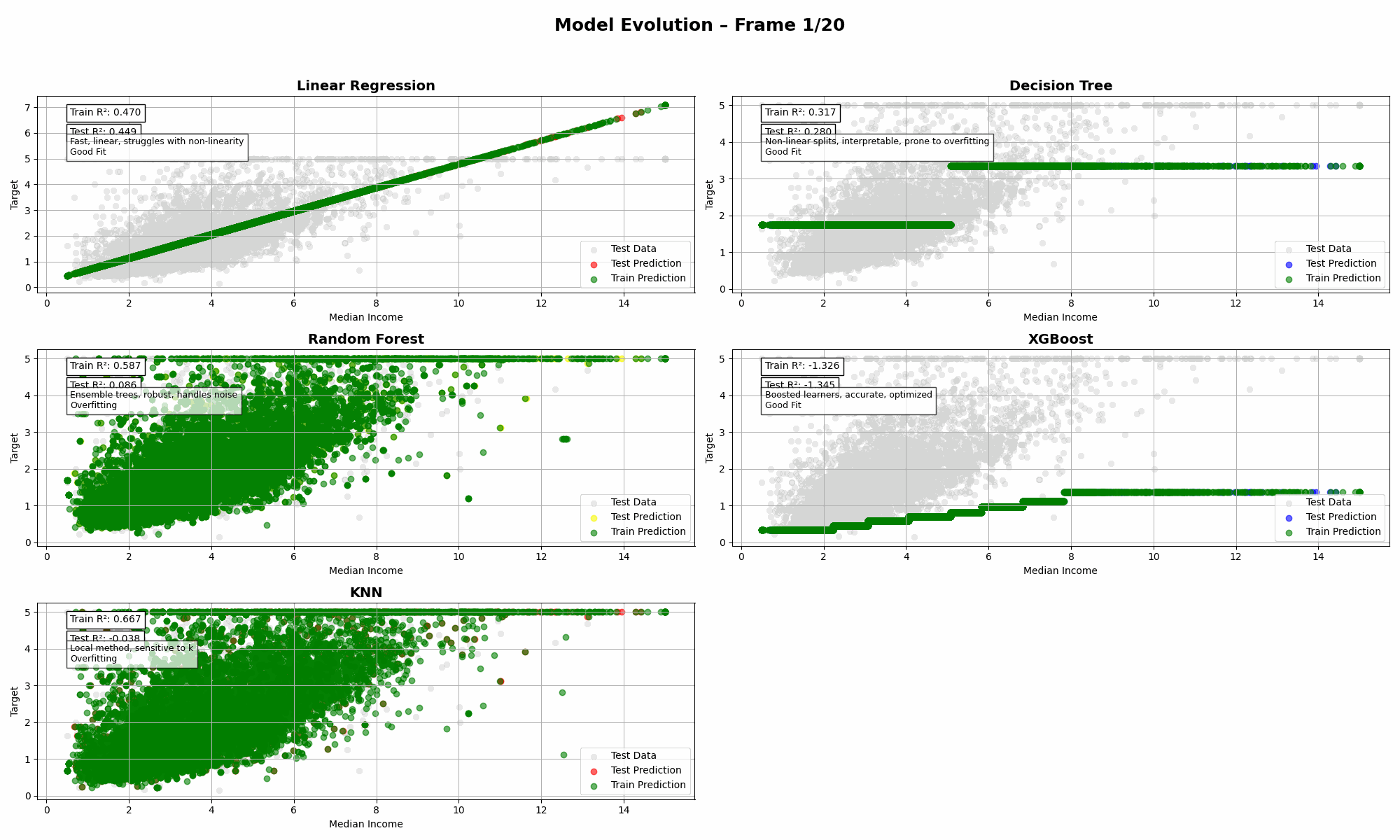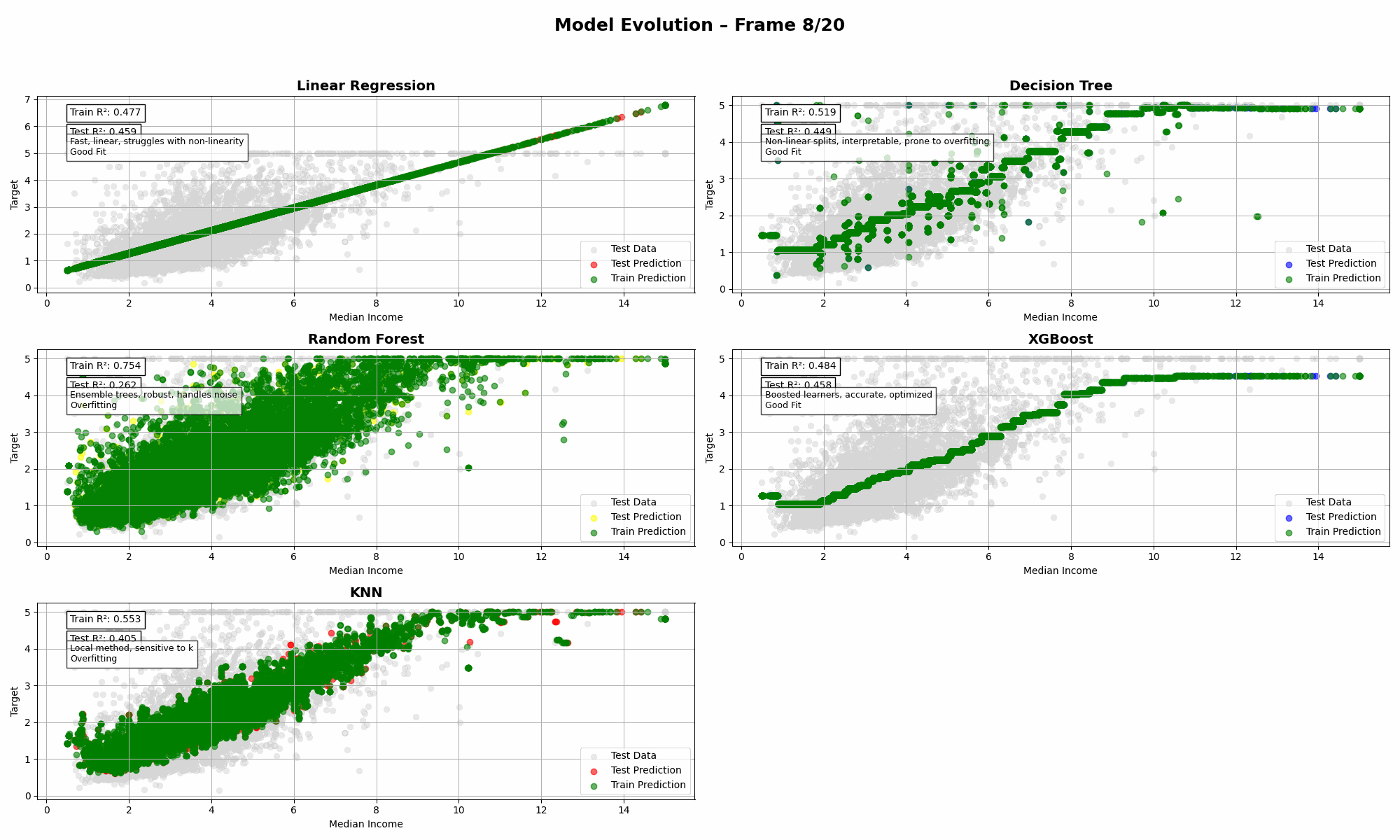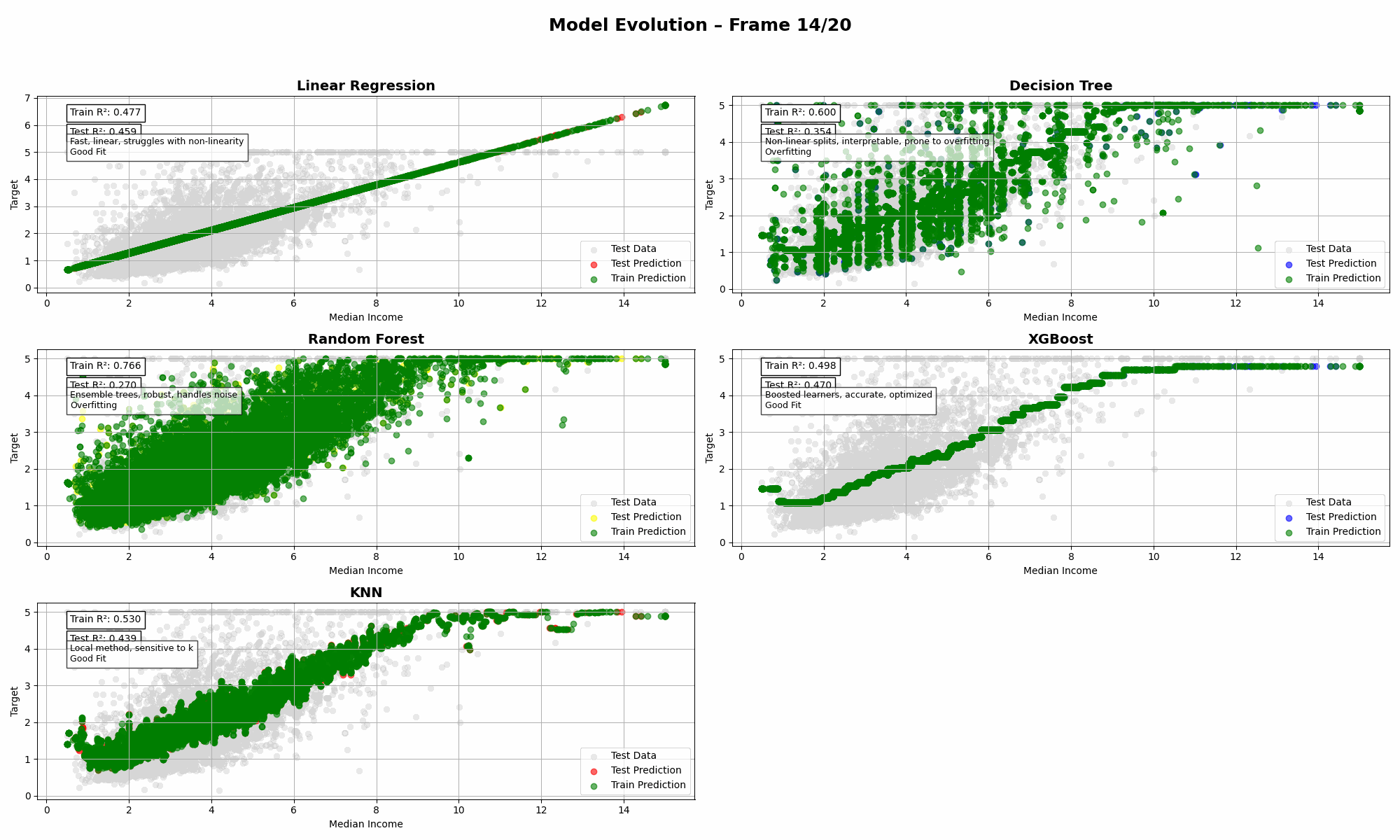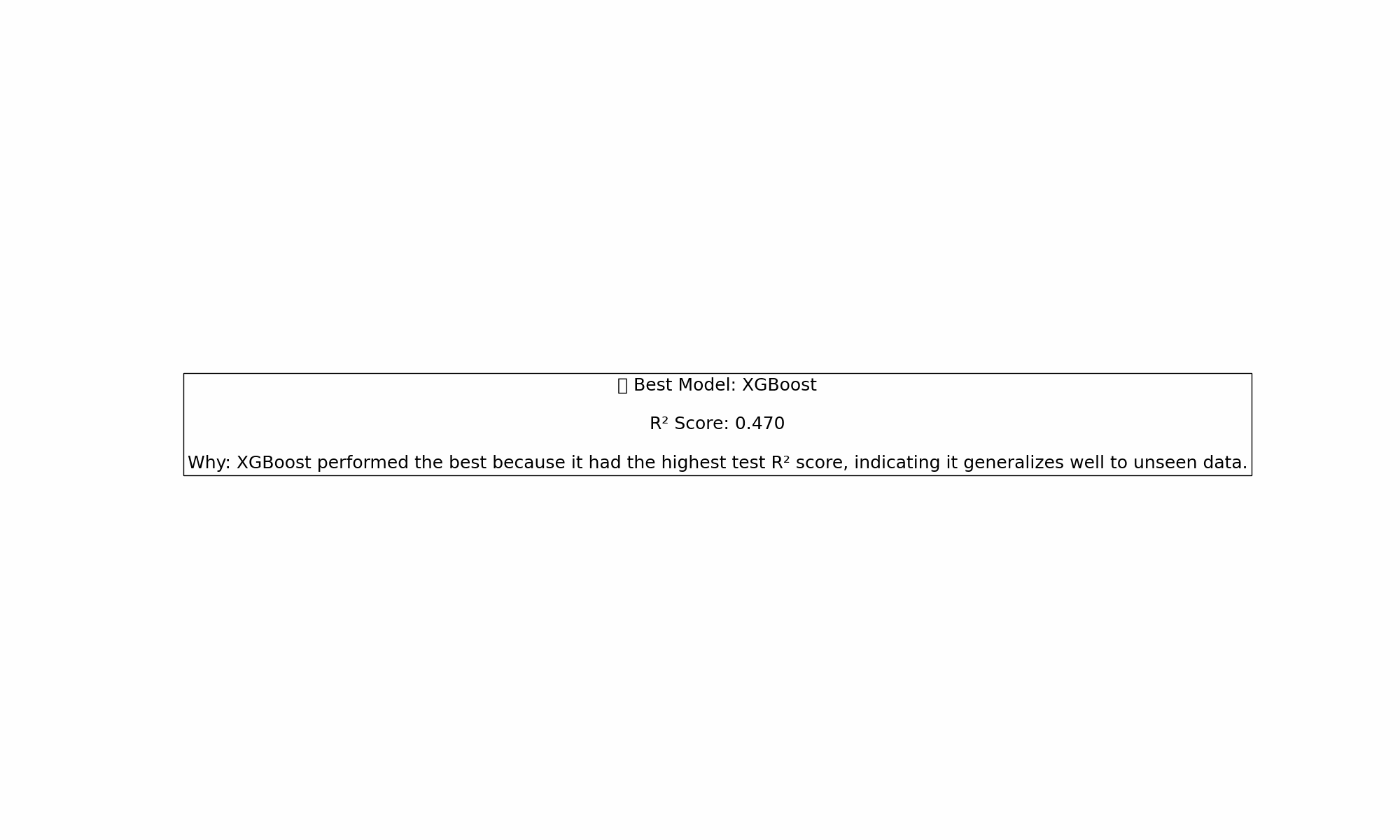
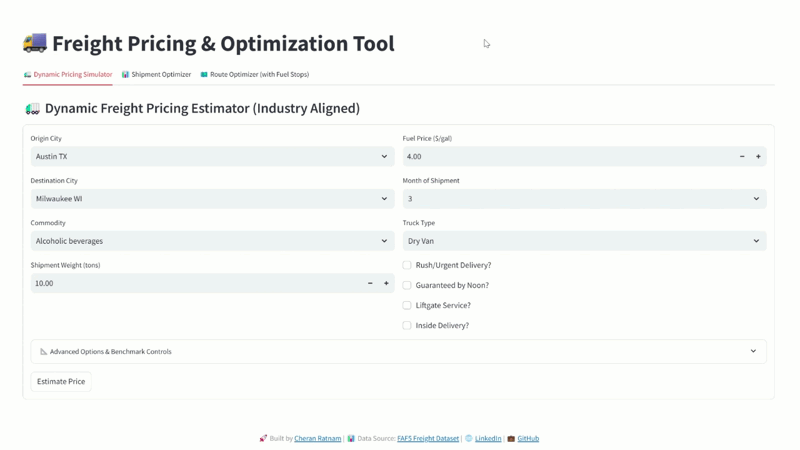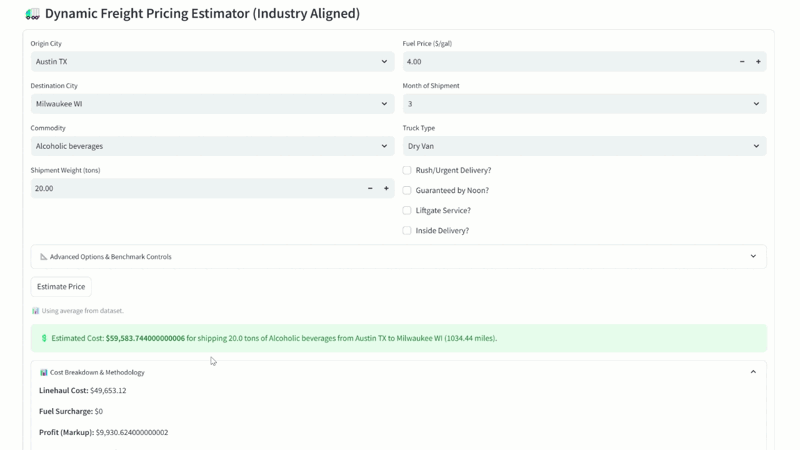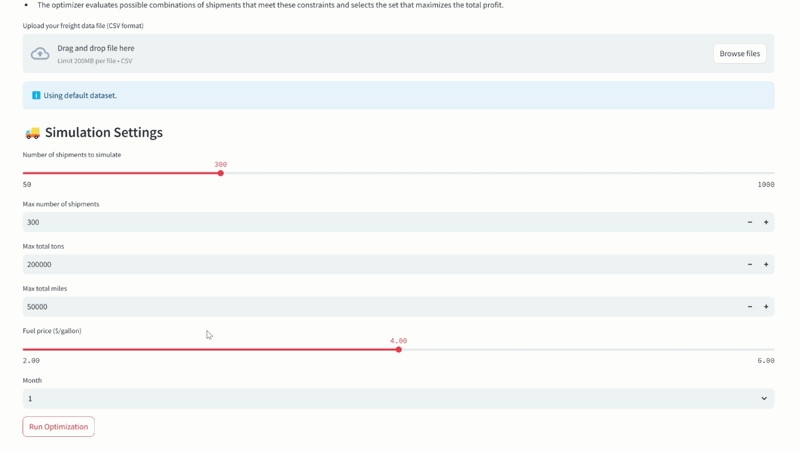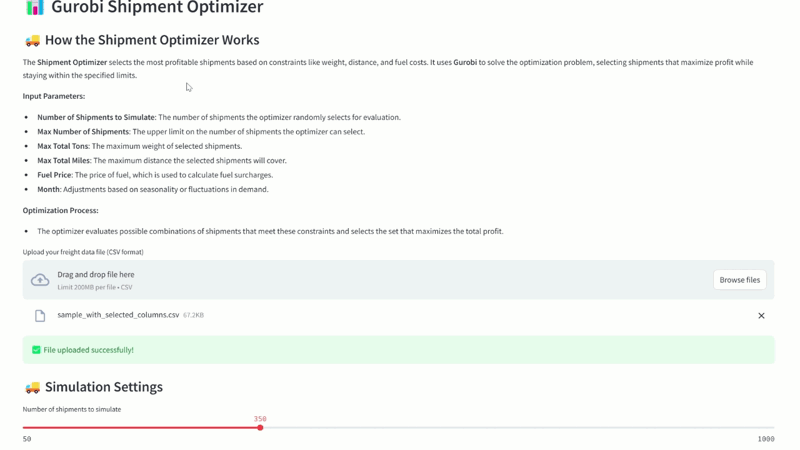
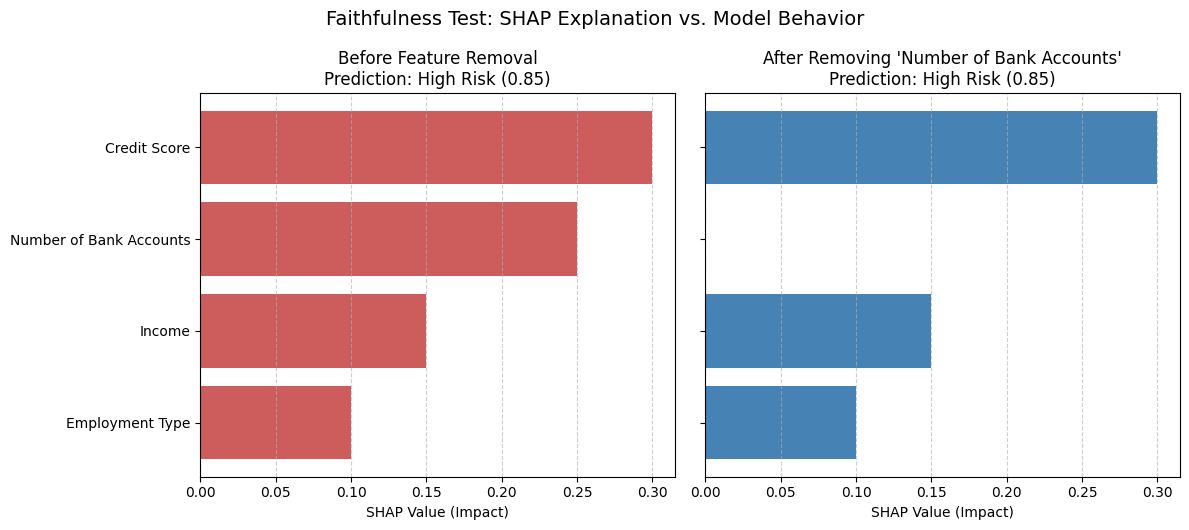
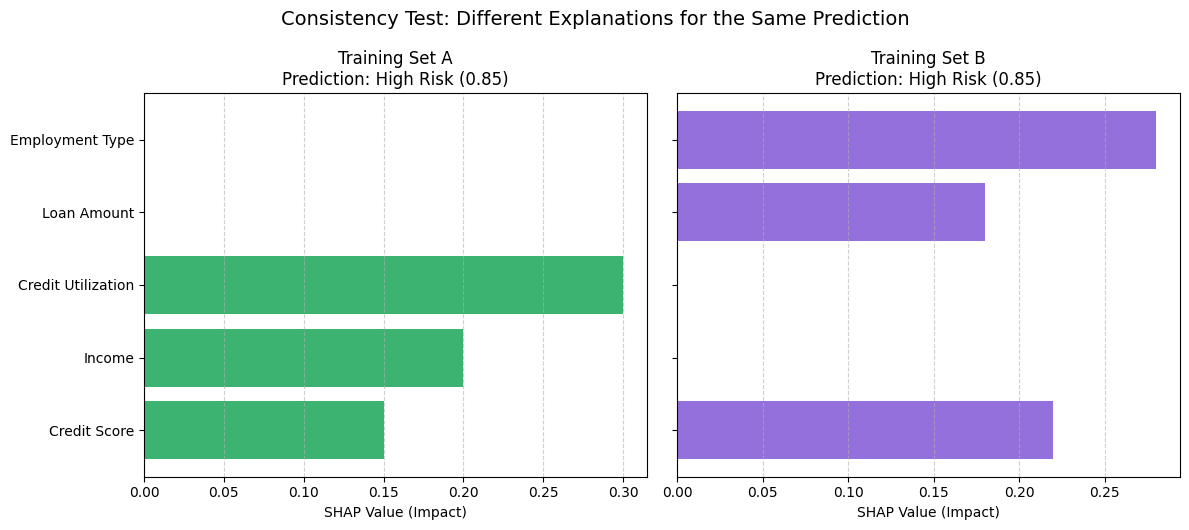
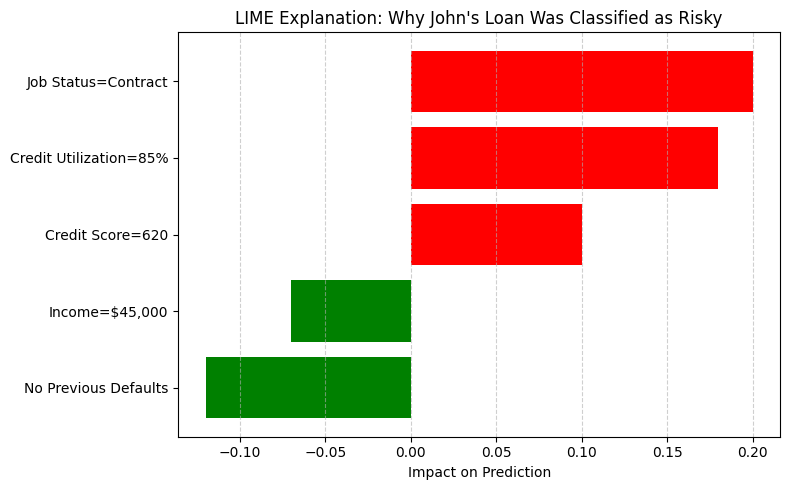
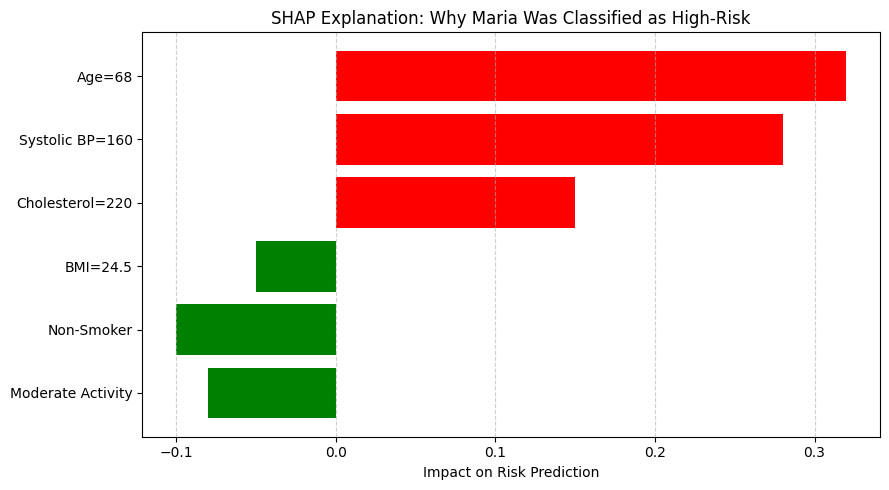
Unsignalized intersections are managed without traffic lights. They rely on stop signs and right-of-way rules. These intersections are inherently riskier compared to traffic light enforced ones because now there is no lights and it depends on the driver paying attention to the stop sign, but that is a different matter altogether.
They’re common in suburban or low-traffic areas but increasingly challenged by growing traffic volumes and the emergence of Connected and Automated Vehicles (CAVs).
These intersections are friction points in modern traffic systems. And the problem often starts with one outdated rule: First-Come-First-Served (FCFS).
First-Come-First-Served
FCFS is a simple scheduling principle: vehicles cross in the order they arrive. If multiple vehicles approach, each waits for the ones ahead (yes, you are supposed to wait if the other person arrives at the stop sign before you) even if their paths don’t conflict.
Why It Falls Short
- No spatial awareness: Vehicles wait even when their paths don’t intersect. This may not be a bad thing if your city or neighborhood has CRAZY drivers but it is not efficient right?
- Ignores vehicle dynamics: No speed adjustments are used to reduce waiting time. Although you may be able to reply to a text or two? NO. Don’t text and drive!
- Creates bottlenecks: Delays increase when vehicles arrive from different directions in quick succession. Oh well, your precious time.
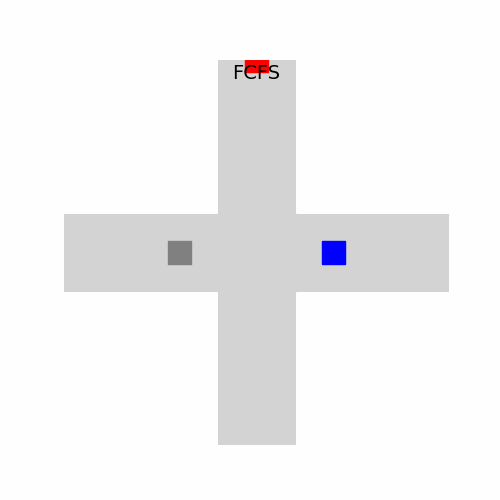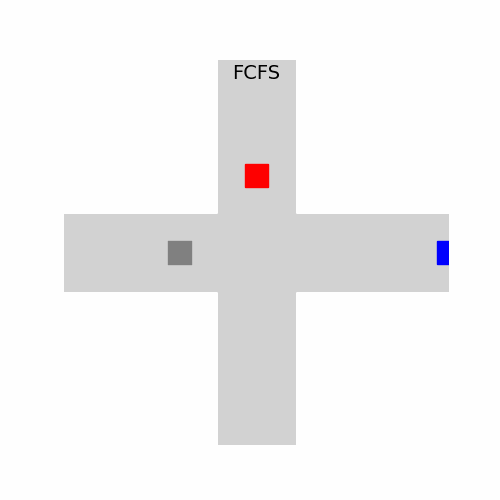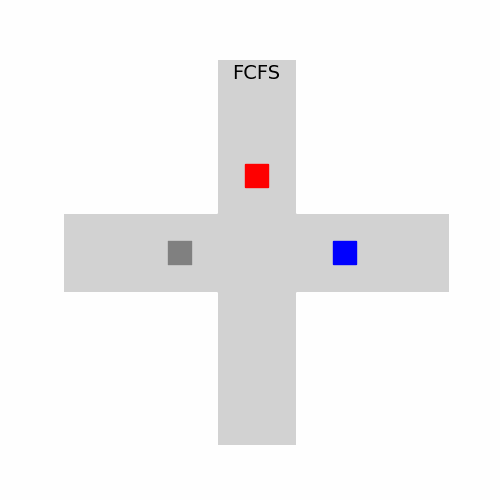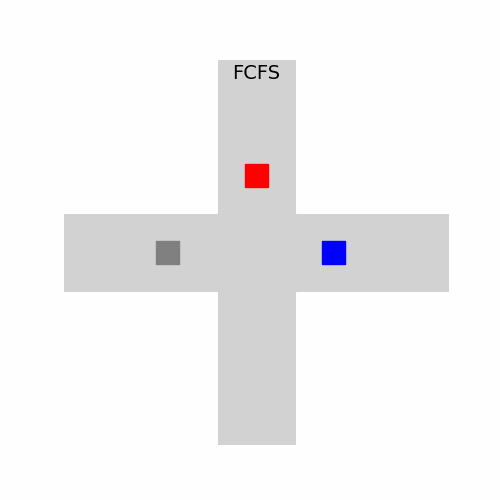
In the animation above, each vehicle waits for the previous one to clear the intersection, even when there’s no collision risk. The result? Wasted time and unused intersection space. Well, that is if you only care about efficiency. Not so bad from a safety point of view.
Why FCFS Doesn’t Work for CAVs
As vehicles become more intelligent and connected, relying on a static rule like FCFS is inefficient. This is assuming that the person behind the wheel is also intelligent enough to practice caution and obey traffic rules and drives SOBER.
Modern CAVs can:
- Share real-time location and speed data.
- Coordinate with one another to avoid collisions.
- Adjust their behavior dynamically.
FCFS fails to take advantage of these capabilities. It often causes unnecessary queuing, increasing delays even when safe, efficient crossings are possible through minor speed changes. Again, assuming that the drivers are all outstanding citizens with common sense, yes, this is not very efficient and there is room for improvement.
A Smarter Alternative: Conflict-Free, Real-Time Scheduling
This recent paper, named “An Optimal Scheduling Model for Connected Automated Vehicles at an Unsignalized Intersection” proposes a linear programming-based model to optimize flow at unsignalized intersections. The model is built for CAVs and focuses on minimizing average delay by scheduling optimal crossing times based on:
- Vehicle location and direction
- Potential conflict zones
Key Features of the Model
- Conflict-free scheduling: Ensures no two vehicles with intersecting paths enter at the same time.
- Rolling horizon optimization: Continuously updates schedules in real time.
- Delay minimization: Vehicles adjust speed slightly instead of stopping.

In this visualization, vehicles coordinate seamlessly:
- The red car enters first.
- The gray car slows slightly to avoid a conflict.
- The blue car times its approach to maintain flow.
No stopping. No wasted time. Just optimized motion.
Now that all sounds good to me. It sounds somewhat like a California Stop, if you know what I mean. But how can we trust the human to obey these more intricate optimization suggestions when people don’t even adhere to more simple rules like slowing down in a school zone? Ok, maybe a different topic. So let’s assume that these are all goody goodies behind the wheel and continue.
Performance: How the Model Compares to FCFS
According to the study’s simulations:
- Up to 76.22% reduction in average vehicle delay compared to FCFS.
- Real-time responsiveness using rolling optimization.
- Faster computation than standard solvers like Gurobi, making it viable for live deployment.
The result? Smoother traffic, shorter waits, and better use of intersection capacity without traffic signals.
Rethinking the Rules of the Road
FCFS is simple but simplicity comes at a cost. In a connected, data-driven traffic ecosystem, rule-based systems like FCFS are no longer sufficient.
This study makes the case clear: real-time, model-based scheduling is the future of unsignalized intersection management. As cities move toward CAVs and smarter infrastructure, the ability to optimize traffic flow will become not just beneficial, but essential. That said, complexity also comes at a cost. If all the vehicles are autonomous and are controlled by a safe, optimized, and centralized algorithmic command center, this could work. But as soon as you introduce free agency, which is not a bad thing, but in this context it introduces a lot of risk, randomness, uncertainty, and CHAOS … one have to think about efficiency vs. practicality and safety.
If these CAVs are able to enter into a semi-controlled environment when they enter the parameter of the intersection, perhaps this approach could work. This means that while they are in the grid (defined by a region that leads up to the stop sign), the driver does loose some autonomy and their vehicle will be simulated by a central command … this might be a good solution to implement.
Either way, this is an interesting study. After all, we all want to get from point A to point B in the most efficient way possible. The less time we spend behind the wheel at stop signs, the more time we have for … hopefully not scrolling Tik Tok. But hey, even that is better than just sitting at a stop sign, right?